Linked Data Notifications: a resource-centric communication protocol
- Identifier
- https://csarven.ca/linked-data-notifications
- In Reply To
- Calls for Linked Research
- ESWC 2017 Call for Papers
- Notifications Inbox
- inbox/
- Annotation Service
- annotation/
- Published
- Modified
- License
- CC BY 4.0
Abstract
In this article we describe the Linked Data Notifications (LDN) protocol, which is a W3C Candidate Recommendation. Notifications are sent over the Web for a variety of purposes, for example, by social applications. The information contained within a notification is structured arbitrarily, and typically only usable by the application which generated it in the first place. In the spirit of Linked Data, we propose that notifications should be reusable by multiple authorised applications. Through separating the concepts of senders, receivers and consumers of notifications, and leveraging Linked Data principles of shared vocabularies and URIs, LDN provides a building block for decentralised Web applications. This permits end users more freedom to switch between the online tools they use, as well as generating greater value when notifications from different sources can be used in combination. We situate LDN alongside related initiatives, and discuss additional considerations such as security and abuse prevention measures. We evaluate the protocol’s effectiveness by analysing multiple, independent implementations, which pass a suite of formal tests and can be demonstrated interoperating with each other.
Keywords
Introduction
Notifications are sent over the Web for a variety of purposes, including social applications: You have been invited to a graduation party!
, Tim commented on your blog post!
, Liz tagged you in a photo
. The notification data may be displayed to a human to acknowledge, or used to trigger some other application-specific process (or both). In a decentralised architecture, notifications can be a key element for federation of information, and application integration. However in centralised systems which prevail today, this data is structured arbitrarily and typically only usable by the application that generated it in the first place. Current efforts towards re-decentralising the Web [1, 2, 3] are moving towards architectures in which data storage is decoupled from application logic, freeing end users to switch between applications, or to let multiple applications operate over the same data. So far, notifications are considered to be ephemeral resources which may disappear after transport, and thus are excluded from being designed for reuse.
We argue that notification data should not be locked into particular systems. We designed the Linked Data Notifications (LDN) protocol to support sharing and reuse of notifications across applications, regardless of how they were generated or what their contents are. We describe how the principles of identification, addressability and semantic representation can be applied to notifications on the Web. Specifying LDN as a formal protocol allows independently implemented, heterogeneous applications which generate and use notifications, to seamlessly work together. Thus, LDN supports the decentralisation of the Web as well as encourages the generation and consumption of Linked Data.
We build on existing W3C standards and Linked Data principles. In particular, the storage of notifications is compatible with the Linked Data Platform standard; notifications are identified by HTTP URIs; and notification contents are available as JSON-LD. A key architectural decision is the separation of concerns between senders, receivers, and consumers of notifications. Implementations of the protocol can play one or more of these roles, and interoperate successfully with implementations playing the complementary roles. This means that notifications generated by one application can be reused by a completely different application, accessed via the store where the notification data resides, through shared Linked Data vocabularies. LDN also pushes the decentralised approach further by allowing any target resource to advertise its Inbox anywhere on the Web; that is, targets do not need to be coupled to or controlled by a receiver, and can make use of a third-party Inbox as a service.
LDN is a W3C Candidate Recommendation via the Social Web Working Group [4]. The first two authors (Sarven Capadisli and Amy Guy) of this article are the co-editors of the specification.
Use cases for decentralised notifications are particularly evident in social networking (status updates, interactions, games); scholarly communication (reviews, citations); and changes of state of resources (datasets, versioning, sensor readings, experimental observations). We describe the requirements which guided the development of the protocol and discuss related work, including current alternative approaches and complementary protocols which can work alongside LDN. We summarise the protocol itself, and specific architectural considerations that were made. We built a test suite which can be used to confirm that implementations conform with the specification, and we describe 17 implementations which interoperate with each other.
As the following terms used throughout this article may be subject to different interpretations by different communities, we provide some definitions here.
By decentralisation, we mean data and applications are loosely coupled, and users are empowered to choose where their data is stored or held. We focus on Web-based decentralisation, where content is transported over HTTP, and resources are identified with URIs. An Inbox is a container or directory (attached to a Web resource) which is used to store and serve a collection of notifications. A notification is a retrievable resource which returns RDF. The contents of notifications are intended to describe a change in state of some other resource, or contain new information for the attention of a user or process, and may be subject to constraints of the Inbox it is contained in.
Requirements and Design Considerations
In this section we discuss our considerations for a Web notification protocol that conforms to the Linked Data design principles, as well as best practices for applications. We use these considerations to establish both concrete requirements and points of implementation-specific flexibility for the protocol.
R1 Modularity
To encourage modularity of applications, one should differentiate between different classes of implementation of the protocol. Two parties are involved in the creation of a notification: a sender, generating the notification data, and a receiver, storing the created resource. We also have the role of a consumer, which reads the notification data and repurposes it in some way. A software implementation can of course play two or all three of these roles; the important part is that it need not. A consuming application can read and use notification data without being concerned about ever sending or storing notifications.
R2 Reusable notifications
The relationship between the consumer and receiver roles is key to notifications being reusable. A consumer must be able to autonomously find the location of notifications for or about the particular resource it is interested in. To achieve this we place a requirement on the receiver to expose notifications it has been sent in such away to permit other applications to access them; and specify how any resource can advertise its receiving endpoint for consumers to discover. To promote fair use or remixing of notification contents, applications can incorporate rights and licensing information into the data. Similarly, applications may include additional information on licensing resources that the notification refers to. The presence of this type of information is important for consumers to assess the (re)usability of data.
R3 Persistence and Retrievability
There is a social expectation and technical arguments for ensuring the persistence of identifiers of Web resources [11]. This is inconsistent with the traditionally ephemeral nature of notifications. Applications may benefit from referring to or reusing notifications if the notifications are known to be available in the long term, or indicate their expected lifespan [12].
A RESTful architecture [13] is well suited for persistent notifications, as it involves organisation of atomic resources, their discovery and description, and a lightweight API for the CRUD (create, read, update, and delete) operations [14]. This enforces the notion that notifications are considered resources in their own right, with their own dereferencable URIs.
We need to consider both the needs of software systems and humans when large amounts of notification data are being generated and shared between diverse applications which may be operating without knowledge of each other. To organise and manage large amount of notifications over time, mechanisms should be in place to break representations of collections of notifications into multiple paged responses that may be easier to consume by applications.
Relatedly, receivers may carry out resource management or garbage collection, or permit consumers or other applications to do so. For example, an application to consume messages might let an authenticated and authorised user ‘mark as read’ by adding a triple to the notification contents.
R4 Adaptability
Linked Data applications benefit from domain-driven designs; that is, functionality being small and focussed on a particular purpose, rather than generic. We believe a notification protocol should be adaptable for different domains, but that there is no need to create multiple domain-specific notification protocols; the fundamental mechanics are the same.
R4-A: Any resource may be the target of a notification. By target, we mean a notification may be addressed to the resource, be about the resource, or for a sender to otherwise decide that it is appropriate to draw the attention of the resource (or resource owner) to the information in the notification body. As such, any Web resource must be able to advertise an endpoint to which it can receive notifications. Resources can be RDF or non-RDF (such as an image, or CSV dataset), and may be informational (a blog post, a user profile) or non-informational (a person).
R4-B: We do not purport to be able to design a notifications ontology which is appropriate for every domain. Thus we consider the contents of a notification to be application specific. From a sender’s perspective, we derive two core principles: a notification can contain any data; a notification can use any vocabulary. From a consumer’s perspective, interoperability between different applications occurs through vocabulary reuse, and shared understanding of terms. This is in accordance with Linked Data principles in general. The practical upshot of this is that a calendar application which consumes event invitations using the RDF Calendar vocabulary is likely to completely ignore notifications containing the PROV Ontology, even if it finds them all stored in the same place. For two independent applications operating in the same domain, a shared understanding of appropriate vocabulary terms is assumed.
However from a receiver’s perspective, exposing itself to receive any blobs of RDF data from unknown senders may be problematic. Thus, R4-C: it should be possible for the receiver to enforce restrictions and accept only notifications that are acceptable according to its own criteria (deemed by e.g., user configuration; domain-specific receivers). This can be used as an anti-spam measure, a security protection, or for attaining application and data integrity.
Rejecting notifications which do not match a specific pattern in their contents, or the shape of the data, is one way to filter. For example, if the Inbox owner knows that they will only ever use a consuming application which processes friend requests, they can configure their receiver to filter out anything that does not match the pattern for a friend request, helping their consumer to be more efficient. If the notification constraints are also advertised by the receiving service as structured descriptions, generation and consumption of the notifications can be further automated. Possible specifications for doing so are W3C Shapes Constraint Language (SHACL) [15] or ShEx.
Receivers may wish to filter notifications by verifying the sender, through for example a whitelist or a Web of trust. This requires an authentication mechanism and since different authentication mechanisms are appropriate for different applications, the notification protocol should ideally be usable alongside various methods such as clientside certificates, e.g., WebID+TLS, token-based, e.g., OAuth 2.0, or digital signatures.
As anyone can say anything about anything
a receiver may choose to resolve any external resources referred to by the notification, and cross-check the notification contents against authoritative sources. This is similar to how Semantic Pingback and Webmention require fetching and parsing of the source URL to verify existence of the target link.
R5 Subscribing
In general, applications may require that new notifications are pushed to them in real-time, or to request them at appropriate intervals. To take this into account, we expand our definition of senders, receivers and consumers with the following interaction expectations: notifications are pushed from senders to receivers; and pulled from receivers by consumers.
Thus, an application which offers an endpoint or callback URL to which notifications should be sent directly is a receiver, and an application which fetches notifications from an endpoint on its own schedule is a consumer. Much of the related work requires notifications to be explicitly solicited to trigger sending. Since in a decentralised model, receivers may not be aware of possible sources for notifications, our sender-receiver relationship depends on the sender’s autonomy to make such decisions by itself. This does not preclude the scenario in which a receiver may wish to solicit notifications from a particular sender, but as there are already subscription mechanisms in wide use on the Web, we do not need to specify it as part of LDN. For example, WebSub (recent W3C evolution of PubSubHubbub), the WebSocket Protocol, or HTTP Web Push.
Given our adoption of Linked Data principles and a RESTful architecture, a further design decision was to ensure minimal compatibility with the Linked Data Platform (LDP) specification [16]. LDP is a RESTful read-write API for RDF resources, which groups related resources together into constructs known as Containers
. Thus, existing LDP servers can be used to store notifications, as new notifications can be created by POSTing RDF to a container.
The LDN Protocol
The Linked Data Notifications (LDN) protocol describes how servers (receivers) can receive messages pushed to them by applications (senders), as well as how other applications (consumers) may retrieve those messages. Any resource can advertise a receiving endpoint (Inbox) for notification messages. Messages are expressed in RDF, and can contain arbitrary data. It is not dependent on a complete implementation of LDP, but comprises an easy-to-implement subset. LDN is a W3C Candidate Recommendation [4].
Sender to receiver interactions
The following steps (in order without skipping) describe the interaction between sender and receiver:
(1) A sender is triggered, either by a human or an automatic process, to deliver a notification; (2) The sender chooses a target resource to send notifications to; (3) The sender discovers the location of the target’s Inbox through the ldp:inbox relation in the HTTP Link header or RDF body of the target resource; (4) The sender creates the body of the notification according to the needs of application; (5) The sender makes a POST to the Inbox URL, containing the body in JSON-LD or in another serialisation acceptable by the server; (6) The receiver optionally applies filtering rules, and sends the appropriate HTTP response code to accept or reject the notification; (7) The receiver exposes the notification data (according to appropriate access control) for use by consumers.
Consumer to receiver interactions
The following steps (in order without skipping) describe the interaction between consumer and receiver:
(1) A consumer selects a target and discovers the location of its Inbox in the same way as the sender; (2) A receiver responds to GET requests made to the Inbox URL with a listing of the URLs of notifications that have previously been accepted, linked to the Inbox with the ldp:contains predicate; (3) The receiver responds to GET requests made to the individual notification URLs with JSON-LD (or optionally other serialisations); (4) Following the retrieval of notification listings or individual notifications, the consumer may perform further processing, combine with some other data, or simply present the results in a suitable human-readable way.
Example Notifications
For more example notification payloads, see the LDN specification.
{"@context": { "sioc": "http://rdfs.org/sioc/ns#" }"@id": "","@type": "sioc:Comment","sioc:content": "This is a great article!","as:inReplyTo": { "@id": "http://example.org/article" },"sioc:created_at": { "@value": "2015-12-23T16:44:21Z" }}
@prefix as: <https://www.w3.org/ns/activitystreams#> .@prefix cito: <http://purl.org/spar/cito/> .<> a as:Announceas:object <https://linkedresearch.org/resources#r-903b83> ;as:target <https://csarven.ca/dokieli#architecture> .<https://linkedresearch.org/resources#r-903b83>cito:citesAsPotentialReading<https://csarven.ca/linked-data-notifications#protocol> .
Implementations
Here we summarise the 17 LDN implementations we are aware of to date. They are built by 10 different teams or individuals using different tool stacks (5 clientside JavaScript, 3 PHP, 3 NodeJS, 3 Python, 1 Perl, 1 Virtuoso Server Pages, 1 Java) and have submitted implementation reports as part of the W3C standardisation process. We note that any LDP implementation is a conforming LDN receiver; we refer here to the ones we have tested. We discuss the value of these implementations further in the Evaluation section.
| Implementation | Class* | Description |
|---|---|---|
Source: https://github.com/w3c/ldn/tree/master/implementations |
||
| CarbonLDP | R | Data storage platform (LDP) |
| dokielia | S,C | Clientside editor and annotator |
| errola | S | Generic message sending client |
| Fedora Commons | R | Open source repository platform (LDP) |
| IndieAnndroid | R | Personal blogging platform |
| Linked Edit Rules | S | Statistical dataset consistency checker |
| mayktsoa | R | Personal data store (LDP) |
| OnScreena | C | Notifications display client |
| pyldn | R | Standalone Inbox |
| RDF-LinkedData-Notifications | R | Standalone Inbox |
| slopha | S,R | Social publishing & quantified self |
| Solid Words | S | Foreign language learning app |
| solid-client | S | Clientside library for LDP |
| solid-inbox | C | Clientside social message reader |
| solid-notifications | S,C | Clientside library for LDN |
| solid-server | R | Personal data storage server (LDP) |
| Virtuoso+ODS Briefcase | R,C | Personal data storage server (LDP) |
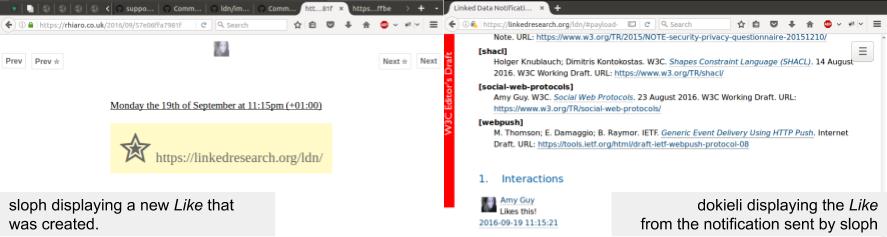
We highlight social scholarly communication use cases with dokieli, a clientside editor for decentralised scientific article publishing, annotations and social interactions [17]. dokieli uses LDN to send and consume notifications: When a reader comments on a fragment of text in an article, the application discovers the article’s Inbox and sends a notification about the annotation. dokieli also consumes notifications from this Inbox to fetch and display the annotation as marginalia (figure 2). A reader can share a dokieli-enabled article with their contacts; dokieli discovers each contact’s Inbox and sends a notification there (figure 3). When editing an article, the author can add a citation. If an Inbox is discovered in the cited article, dokieli sends a notification there to indicate what part of the article was cited by whom and where. dokieli-enabled articles also consume citation notifications to display these metrics for the author and other readers (figure 4).
Notifications sent by dokieli can be reused by any consuming applications that recognise the vocabulary terms; similarly, dokieli can consume notifications sent by different applications.
Further social use cases are demonstrated by sloph, a personal publishing and quantified self platform which acts as a node in a decentralised social network. When new content is created on the server, sloph performs discovery on URLs it finds as values of particular properties of the new content, as well as any URLs in the body of the content, and sends notifications accordingly. For instance:
- If a Like activity is generated on the server, sloph uses the
objectof the Like as the target for a notification. Since dokieli uses the same vocabulary for social interactions (ActivityStreams 2.0 [18]), if the target is a dokieli article, this Like will be displayed (figure 5). - If the user publishes a blog post containing a link, which may be semantically annotated to indicate the reason for linking, sloph sends a notification to any Inbox discovered at that link.
- As a receiver, sloph accepts all incoming notifications, but holds for moderation (i.e. places behind access control) any that it cannot automatically verify refer to third-party content published on another domain. If an article written with dokieli publishes a citation of a blog post which advertises a sloph Inbox, sloph will fetch the article and verify whether the relation matches the contents of the notification before exposing the notification for re-use.
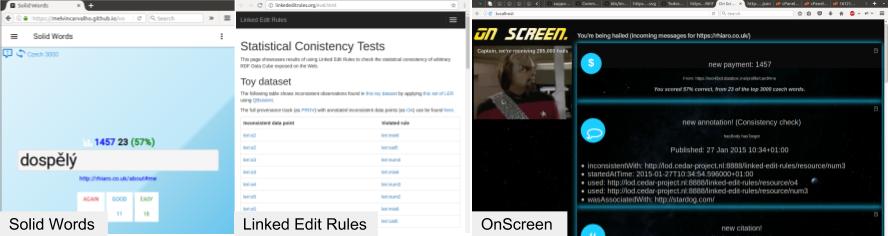
Linked Edit Rules and Solid Words are specialised senders. Linked Edit Rules checks the consistency of statistical datasets against structured constraints, and delivers the consistency report as a notification to the user. Solid Words is a clientside game for learning new words in a foreign language; it delivers the player’s score for each round to their Inbox. OnScreen is a (crude) generic consumer; as such, it can display notifications sent by both of the aforementioned senders (figure 6).
Analysis and Evaluation
The LDN protocol describes the discovery of a resource’s Inbox whence notifications are sent or consumed, and the sending and exposure of those notifications. Here we analyse how well features of LDN achieve the requirements identified previously, and compare this to related work.
We have already examined implementations of the specification and described how they interoperate with each other; this can be further tested by running the test suite: https://linkedresearch.org/ldn/tests/. We can use this towards an evaluation of its feasibility and effectiveness at interoperability. Given the relatively early stage in the standardisation process (LDN entered Candidate Recommendation in 2016-11), the fast adoption of the LDN specification, quantity of the implementations, and their diversity is promising and further shows LDN’s feasibility. Furthermore, during the development of the specification issues have been raised or discussed by 28 different people (excluding the authors; 21 outside of the Social Web Working Group, 7 within) and the specification has undergone formal review by internationalisation, accessibility, and security specialists. We also discuss in more depth particular challenges that were raised and resolved as part of this process.
Comparison summary
Here we compare existing notification mechanisms from related work. The criteria includes our requirements and design considerations (Rx) along with additional technical information which helps to capture some design differences (Tx).
| Mechanism | T1 | T2 | T3 | R1 | R2 | R3 | R4-A | R4-B | R4-Cp | R4-Cv | R4-Co | R5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|||||||||||||
| Semantic Pingback | Linkback | POST | RDF | S R | / | / | Anyr | form urlencodedk | ! | ! parse source | Anyr | X | |
| Webmention | Linkback | POST | HTML | S R | – | – | Anyh | form urlencodedk | ! | ! parse source | Anyh | X | |
| Provenance Pingback | Linkback | POST | RDF | S R | / | / | / | URI list | / | / | RDFq | X | |
| DSNotify | Fat ping | POST, PUT | XML, PuSH | S U | / | – | – | XML | / | – | RDFt | ! | |
| sparqlPuSH | Fat ping | POST | XML, SPARQL, PuSH | S U | – | – | – | XMLra | / | – | RDFt | ! | |
| ResourceSync | Fat ping | POST | XML, PuSH | S U | / | – | – | XMLs | / | – | ? | ! | |
| Linked Data Notifications | Fat ping | POST | JSON-LD | S R C | ! | ! URI | Any | JSON-LDj | + app | + app | – | O app | |
Given that each application requires to follow the steps listed in Sender to receiver interaction
and Consumer to receiver interactions
the metrics are dependent on the performance of client and server to do HTTP requests and responses, and their respective payloads.
Compatibility with existing systems
Per R1 and R4 we have tried to optimise LDN for use as a module of a larger system. The success of this is demonstrated by implementations which use LDN alongside existing protocols according to their specific needs.
The Solid suite of tools, Virtuoso+ODS-Briefcase, and dokieli use Web Access Control along with an authentication mechanism to apply fine grained access controls to restrict who can send notifications, or who can retrieve notifications from the Inbox. sloph demonstrates an Inbox as a Webhooks callback URL, for requesting notifications from APIs which post JSON-based payloads. ActivityPub is a W3C CR for decentralised social media [19]. It uses LDN for delivery of notifications with the ActivityStreams 2.0 (AS2) vocabulary, and specifies additional specialised receiver behaviour; also used by sloph. dokieli uses the Web Annotation Protocol, an LDP-based mechanism for creating new content, which acts as a trigger for notifications to be sent to the Inbox of the annotation target. The Fedora API Specification is in the process of being formalised (as an extension of LDP) by the Fedora community. The repository event stream draws upon the LDN specification, allowing LDN consumers and senders to react asynchronously to repository events.
Any existing LDP implementation can serve as an LDN receiver. Simply advertising any ldp:Container as the Inbox for a resource is sufficient. We confirmed this with four LDP servers which were developed independently with different code bases, prior to the LDN specification (CarbonLDP, Fedora Commons, Solid Server, Virtuoso).
LDN has been integrated into existing domain specific systems: dokieli, Fedora Commons, IndieAnndroid, Linked Edit Rules, sloph, solid-client, Solid Words. Standalone implementations of LDN are also straightforward as a result of this modularity, ie: errol, mayktso, onscreen, pyLDN, RDF-LinkedData-Notifications, solid-inbox, solid-notifications.
Optimising implementation
We have considered tradeoffs between the HTTP operations receivers and publishers are required to respond to, and ways in which developers may wish to optimise senders or consumers by reducing outbound requests.
HEAD requests are low cost, and GET requests may be high cost if the body of the resource is large.
Given that an Inbox may be discovered from the HTTP headers of a resource, senders and consumers can optimise by attempting a HEAD request for discovery, and only continuing with a GET request if the HEAD is not successful. On the other hand, senders and consumers may be attempting discovery upon RDF resources which they already intend to parse into their own storage. In this case, there is no need for a HEAD request, as a GET will yield both HTTP Link headers and an RDF body, either of which could include the Inbox triple. This means that resources advertising an Inbox must respond to GET requests (even if only with HTTP headers) and may respond to HEAD requests.
Data Formats and Content Negotiation
Handling data irrespective of the particular RDF serialisation permits some flexibility, but can be costly to support. We take into account: (a) application interoperability, (b) maintenance of RDF parsers and serialisation libraries, (c) complexity of their inclusion in applications, (d) run-time efficiency.
To address these issues, LDN requires all applications to create and understand the JSON-LD syntax, both for the contents of Inbox as well as for individual notifications. Choosing a single serialisation to require is necessary for consistent interoperability, as well as keeping processing requirements or external code dependencies minimal. JSON-LD is advantageous in being familiar for developers who are used to JSON-based APIs but not RDF [20], and it is compatible with existing JSON libraries or in some cases native programming language data structures.
Optionally, applications may attempt to exchange different RDF serialisations by performing content negotiation (receivers can expose Accept-Post headers for senders, and consumers can send Accept headers to receivers).
Precision
In placing no constraints on the contained information, LDN enables a sender to be precise and lossless with the data it is transmitting. Approaches which send only URLs rely on the receiver interpreting a third-party resource, which may or may not contain structured markup or be under the control of the sender. Approaches which offer additional guidance to aid the receiver in interpreting the source document(s) nonetheless still restricts the sender. LDN therefore offers flexibility to senders, increasing the potential uses for the notification mechanism. LDN compensates for increased complexity on the receiver’s end by recommending filtering mechanisms, and moving some of the burden of understanding notifications to the consumer role. As such LDN can cover a broader variety of use cases.
Accommodating different targets
Per R4 Adaptability, we want LDN to be available for all resources in any publishing context. We consider lowering the bar for publishers of target resources to be a worthwhile trade-off against slightly increased complexity for senders and consumers. This is why we require that senders and consumers must be equipped to discover Inboxes through both HTTP headers and RDF content.
Since binary formats such as images and video cannot contain an RDF relation, the HTTP header is essential for including them. It also allows the inclusion of resources for which it is undesirable or impractical to add individual Inbox relations, such as to elements in a dataset; or circumstances where the developer responsible for the Inbox relation is unable to modify the content. Conversely, non-informational resources (represented with fragment URIs or 303 redirects) are unable to express HTTP headers. Their relation to an Inbox must be expressed in an RDF source. However, if a sender or consumer has a domain-specific requirement to only ever target non-informational resources, they are exempt from the requirement of discovery via HTTP headers.
Conclusions
In this article we describe LDN, a protocol for decentralised semantic notifications, currently undergoing standardisation at the W3C. Key elements are:
- Notifications as retrievable, reusable entities with their own URIs.
- Distinct conformance classes for senders, receivers, and consumers.
- Deliberately not defining the vocabulary of notification contents to allow for use in a range of different application domains.
- Flexibility of authentication and verification, for the same reason.
We outlined design requirements, describe how LDN meets these, and compare this with related work. We consider LDN to have greater modularity and adaptability to different scenarios, as well as good conformance with Linked Data principles. This specification has potential to have high impact in increasing interoperability between decentralised Linked Data applications in related domains, as well as generating new discoverable content for the LOD Cloud. This is evidenced by 17 diverse implementations which can be shown to interoperate with each other, including generic libraries and datastores, and domain-specific applications. Being on the W3C standards track increases the likelihood of further adoption.
Acknowledgements
This material is based on work supported by the Qatar Computing Research Institute (QCRI), and by the DFG project “Opening Scholarly Communication in Social Sciences” (grant agreement AU 340/9-1).
References
- Mansour, E., Sambra, A., Hawke, S., Zereba, M., Capadisli, S., Ghanem, A., Aboulnaga, A., Berners-Lee, T.: A Demonstration of the Solid Platform for Social Web Applications, WWW, Demo, 2016, http://www2016.net/proceedings/companion/p223.pdf
- Tramp, S., Frischmuth, P., Ermilov, T., Shekarpour, S., Auer, S.: An Architecture of a Distributed Semantic Social Network, Semantic Web Journal, 2012, http://www.semantic-web-journal.net/sites/default/files/swj201_4.pdf
- Arndt, N., Junghanns, K., Meissner, R., Frischmuth, F., Radtke, N., Frommhold, M., Martin, M.: Structured Feedback, WWW, LDOW, 2016, http://events.linkeddata.org/ldow2016/papers/LDOW2016_paper_02.pdf
- Capadisli, S., Guy, A.: Linked Data Notifications, W3C Candidate Recommendation, 2016, https://www.w3.org/TR/ldn/
- Parecki, A.: Webmention, W3C Proposed Recommendation, 2016, https://www.w3.org/TR/webmention/
- Langridge, S., Hickson, I.: Pingback 1.0, 2002, http://www.hixie.ch/specs/pingback/pingback
- Klyne, G., Groth, P.: PROV-AQ: Provenance Access and Query, W3C Note, 2013, http://www.w3.org/TR/prov-aq/
- Haslhofer, B., Popitsch, N.: DSNotify – Detecting and Fixing Broken Links in Linked Data Sets, WWW, 2010, http://eprints.cs.univie.ac.at/81/1/2010_WWW_DSNotify.pdf
- Passant, A., Mendes, P.N.: sparqlPuSH: Proactive notification of data updates in RDF stores using PubSubHubbub, SFSW, CEUR Workshop Proceedings, Vol. 699, 2010, http://ceur-ws.org/Vol-699/Paper6.pdf
- Klein, M., Van de Sompel, H., Warner, S., Klyne, G., Haslhofer, B., Nelson, M., Lagoze, C., Sanderson, R.: ResourceSync Framework Specification – Change Notification, 2016, http://www.openarchives.org/rs/notification/1.0/notification
- Berners-Lee, T.: Cool URIs don't change, W3C, 1998, https://www.w3.org/Provider/Style/URI.html
- Archer, P., Loutas, N., Goedertier S., Kourtidis, S.: Study On Persistent URIs, 2012, http://philarcher.org/diary/2013/uripersistence/
- Fielding, R. T.: Architectural Styles and the Design of Network-based Software Architectures. Doctoral dissertation, University of California, Irvine, 2000, http://www.ics.uci.edu/~fielding/pubs/dissertation/rest_arch_style.htm
- Page, K.R., De Roure, D.C., Martinez, K.: REST and Linked Data: a match made for domain driven development?, WWW, WS-REST, 2011, http://ws-rest.org/2011/proc/a5-page.pdf
- Knublauch, H., Kontokostas, D.: Shapes Constraint Language, W3C Working Draft, 2016, https://www.w3.org/TR/shacl/
- Speicher, S., Arwe, J., Malhotra, A.: Linked Data Platform, W3C Recommendation, 2015, https://www.w3.org/TR/ldp/
- Capadisli, S., Guy, A., Auer S., Berners-Lee, T.: dokieli, 2016, https://csarven.ca/dokieli
- Snell, J., Prodromou, E.: Activity Streams 2.0, W3C Candidate Recommendation, 2016, https://www.w3.org/TR/activitystreams-core/
- Webber, C., Tallon, J.: ActivityPub, W3C Candidate Recommendation, 2016, https://www.w3.org/TR/activitypub/
- Sporny, M.: JSON-LD and Why I Hate the Semantic Web, 2014, http://manu.sporny.org/2014/json-ld-origins-2/
Interactions
12 interactions
Sarven Capadisli replied on
This image will be updated from time to time to include the changes, e.g., social interactions, on this resource.
Ruben Verborgh replied on
This document presents Linked Data Notifications, a protocol for the exchange of interoperable messages between different applications. The work by itself is highly relevant and a crucial building block for decentralized applications on the Web. What I’m missing in this document (but this is fixable) is a clearer need and urgency from the beginning, perhaps more strongly tied to use cases. Its description makes LDN feel too much as “nice to have” rather than “crucial”, even though the requirements section makes some points clear (but not their urgency nor relation to use cases). Both in the discussion of related work and in the evaluation, I’d like to see a deeper understanding of current limitations, and how LDN addresses is and at what cost. More specifically, what are the problems of LDN, and are they inherent or fixable? In general, several conclusions are left open to the reader; the text can be more explicit about what is good and bad; paragraphs can be written in a more purpose-driven way such that it is always clear where the text is are going and what point it aims to make.
Abstract
- It is confusing that the first sentence talks about “Linked Data Notifications”, and the second continues with “Notifications”—even though they are talking about different things. Therefore, some might read this as “The information contained within a [Linked Data] notification is structured arbitrarily”, which is of course not true. Perhaps move the first sentence to a later point?
- The problem and its urgency are insufficiently clear. Currently, it is written as a couple of nice to haves, such as “more freedom”, “greater value”. Why is it a problem that notifications are only usable by those who generate it? The reader still needs to connect the dots, whereas I expect the text to do this explicitly.
Introduction
- The opposition of decentralized and centralized systems is not fully accurate. The current explanation is that notifications in decentralized systems can be a key element, but that they are arbitrarily structured in centralized systems. However, it is the other way round: current systems currently structure messages arbitrarily, because they are the only consumers of these messages. If we want to decentralize this, the messages need to have a similar structure. So structure is an additional requirement of decentralization, and I would suggest to write it down as such. (Additionally, I’m not sure about “typically only usable by the application that generated it”: why would systems consume their own notifications? Aren’t these for humans anyway?)
- As in the abstract, I think that the need is not sufficiently clear. What scenarios do you want to enable that are difficult or impossible today? One paragraph mentions use cases, but it comes quite late and feels more as a list of examples rather than motivating use cases. Furthermore, the current problems in those use cases are not listed.
- Several technical decisions are mentioned, but their reasons are not. Why was the mentioned key architectural decision taken? I’d say that, in the introduction, the rationale is far more important than the decisions.
- The list of definitions at the end doesn’t seem to come at the right place. The term “Inbox” has been used previously. The definition of a notification as a “retrievable resource which returns RDF” is incompatible with the resource/representation notions of HTTP. I would suggest to define a notification independently of RDF. You can say the resource has RDF representations, but a resource doesn’t “return” anything.
Related Work
- I’m missing the overall notion here of how notifications conceptually work, as we dive straight into the details. Perhaps a figure would be helpful here.
- Crucially, I’m missing a discussion of the limitations of existing approaches. Why are some of the things you list, like “no way to distinguish between multiple potential mentions” an actual problem?
- Should there be some common use cases of notifications here?
Requirements and Design Considerations
- In general, clear and insightful. It could become even stronger if supported by guiding use cases in the preceding sections.
- (Minor) The implied link between REST and lightweight API/CRUD is not technically correct.
- For R4, sketching use cases above in more detail might be helpful.
- R4-B can maybe zoom into partial/layered understanding thanks to Linked Data; I think this is crucial for intelligent systems. For instance, a receiver might say “you received a calendar appointment”, whereas a more specialized receiver says “you have a meeting with X and Y”.
- (Minor) I’d place R4-C at the start of a paragraph, like the others, for scanability.
The LDN Protocol
- It seems strange that “the sender chooses a target resource to send notifications to”. It seems to me this would either be given by the notification, or through a subscription mechanism. The sender probably doesn’t have a lot of “choice” in this.
- Is JSON-LD a hard requirement? Can’t clients and servers agree at runtime about the serialization?
- In general, nice resource-oriented design of the protocol.
- A comparison table between LDN and the other protocols mentioned in Related Work could be insightful.
Implementations
- The videos clarify a lot. Maybe they even can come earlier as motivating examples. I would suggest to perhaps create a use case section for this early on.
- The examples about the specialised senders are very exciting. Checking consistency isn’t something I had initially thought of with notifications, maybe it is good to emphasize such uses as well, which clearly go beyond traditional applications. I’m also seeing a link here with things such as GitHub and continuous integration.
Analysis and Evaluation
- This section appears to be a verification rather than an evaluation. Given the scope of the document, a qualitative evaluation would indeed be a possibility. For instance, an insightful comparison of the shortcomings of existing systems and the benefits of the proposed system, followed by a discussion of the trade-offs that were necessary to realize those benefits.
- On a similar note, it is unclear what each of the sections exactly evaluates. “Comparison summary”: what is the result of the evaluation here? “Compatibility with existing systems”: this is perhaps the clearest, but the conclusion about compatibility is implicit. “Optimizing implementation[s]”, “Data Formats and Content Negotiation”: what is evaluated? “Accommodating different targets”: how well is LDN doing compared to the others?
- It seems that the linked test suite is still incomplete: its “use these tests” section if relatively empty. As such, it us unclear how it can be “[used] towards an evaluation of its feasibility”.
- I don’t find the comparison summary too insightful. I’m not sure what I’m supposed to see in the table. What is good and bad? What is important, what is desirable? I would suggest to highlight the problems and assets somewhat more clearly.
- The purpose of the section “Optimising implementation[s]” is unclear to me. The statements that “HEAD requests are low cost” and “GET requests may be high cost” is underspecified; what is a cost and for whom? You just seem to be talking about bandwidth here, which is not the only cost.
- The decisions regarding content negotiation are appropriate and future-proof.
Conclusions
- Not too many conclusions here, unfortunately; only a summary. What are the lessons learned? What would you do differently next time? How do your findings generalize to to other domains? What impact can this have (this is minimally stated) and why? What is needed/still needs to be done to have such an impact?
Other remarks
- There seem to be additional fields at the bottom (author, published) that are not relevant here.
- This is subjective, but I find the reposted/liked/… stream at the bottom hard to follow. Given the central importance of such social interactions to the topic, it might be worthwhile to simplify their presentation.
Anonymous Reviewer replied on
The article presents the Linked Data Notifications (LDN) protocol, a candidate W3C recommendation, and how it relates to similar notification protocols. Starting with requirements based on Linked Data design principles and the need for re-decentralisation of the Web the article makes a structured comparison of notification mechanisms today and discusses the various implementations of LDN.
This is an architecture type of article in which the requirements and design considerations (section 3) are the base on which the rest of the contribution is built; naturally, some of those requirements are based on opinion but this is exactly the kind of topic to present at ESWC to foster fruitful discussion. For example, the requirement for reusability could be seen as a potential risk for privacy; what is the benefit of reusable notifications to balance that risk? Who would benefit the most from this principle (users, application developers, other) and in what way? A similar discussion could be made for R3 (persistence and retrievability).
It would help if those requirements were discussed a little more in the paper and if they could be placed more clearly in the wider framework/paradigm of Web re-decentralisation (including stakeholders) to give a sense of ‘completeness’ when it comes to notification protocols.
One final point is that certain references (e.g. [3] do not seem to be cited in the text).
1 interaction
Sarven Capadisli replied on
Once fetched by a 3rd-party, any piece of information could potentially be subject to privacy. Hence, this is orthogonal to whether the notifications are ephemeral or persistent. In R4-C, we briefly touch on various authentication methods which could be used alongside LDN with the idea that notifications are not necessarily public but only visible or reusable by intended parties. The receivers decide (based on their use case) which consumers (based on any criteria) can reuse. They achieve this by setting authentication and authorization settings on the notifications.
Anonymous Reviewer replied on
LDNs provide an important mechanism for the current effort (as described in the paper) to re-decentralise the web. The paper is well written. It describes the motivation for LDNs, gives examples and compares LDNs to related efforts.
I have only minor comments:
- one may add in section 2 "related work" a mention of atomPub , and add this also to table 2 "comparison of notification mechanisms"
- for the standardisation process of LDNs this may not be crucial, but one may want to examine benchmarks for notification processing. This could help to evaluate different LDNs applications in terms of their performance. This criterion may become critical during broad adoption, with billions of notifications generated every day.
1 interaction
Sarven Capadisli replied on
We agree that this is an important metric to have for conforming applications. We have highlighted as one of the requirements of the design (R3), e.g., anticipating the possibility of multi-page responses, but the LDN specification leaves this to other, existing standards. However, we do not currently have such data from conforming applications.
Anonymous Reviewer replied on
This paper presents a communication protocol for Linked Data Notifications, reusable messages on the Web that follow the Linked Data principles.
The paper is generally well written and easy to follow. The authors motivate their work well and provide a detailed description of the protocol and its implementations.
Strong points
- The requirements for the protocol are well established.
- The protocol itself is well formalised and described.
- Existence of a number of implementations, both standalone ones and the ones developed previously to the LDN.
- Protocol flexibility and the compatibility with the Linked Data Platform.
- The work is quite relevant.
Weak points
The lack of a real evaluation. Section 6, although titled "Analysis and Evaluation", is actually a comprehensive analysis and discussion of various aspects of the presented work. Section 6.1 is the closest to the evaluation of the work, however the level of details in this section is not satisfactory in that regard. The authors could maybe extend this section with an in depth analysis of the differences between their work and other system that are mentioned, and a discussion on why these differences are important and how LDN provides improvements over them.
Other comments
In the abstract, the authors state: "This permits end users more freedom to switch between the online tools they use, as well as generating greater value when notifications from different sources can be used in combination." Maybe it would be interesting if the authors could mention a few use cases of this added value in a separate section as a strong point for the motivation of the work.
In my opinion, the definition of notification is quite broad and not very clear ("A notification is a retrievable resource which returns RDF"). Is my URI a notification? A URI of an ontology class?
Further explanation perhaps clarifies a bit, but the whole context should be clear in the first sentence.
The interaction steps between consumer and receiver (Section 4.2) might be a bit confusing to the reader. Does step (3) always follow step (2), e.g., the consumer first asks for the listing of notifications and then choses one to retrieve, or it is possible to have only one of the two steps before step (4), e.g., the consumer decides whether it is interested in the listing, or individual notification, or perhaps both.
Also, in my opinion comparing to Section 4.1, the steps in Section 4.2 are described with less detail and rigour.
In Section 5 the authors state: "We note that any LDP implementation is a conforming LDN receiver; we refer here to the ones we have tested". Maybe the authors could mention the reasons why other LDP implementations are not tested, or how they have chosen the implementations that are tested.
The figures in Section 5 are not very readable in the printed version. I understand that the online version of the article reads better, but the authors should maybe consider improving the representations in printed form.
The conclusions section presents only a summary of the paper. But what are the conclusions? Are there any limitations of the presented work and if so which ones? Is there any future work planned?
Not all figures and tables are referenced in the text, I would suggest the authors to include these references.
Reference [3] is not referenced in the text.
In my opinion, the references section could be improved. For example, conference and workshop abbreviations could be extended, exact workshops mentioned (e.g., in [9]). Furthermore, links are omitted in the printed version of the paper which makes the section strange and it is not clear what is the type of the work that is referenced (e.g., conference, technical report, web article, technical specification)
1 interaction
Sarven Capadisli replied on
In the Introduction section we mention the possibility of decoupling application logic from storage, and thus freeing end users to switch between applications, or to let multiple applications operate over the same data
. Also to support sharing and reuse of notifications across applications, regardless of how they were generated or what their contents are.
As per the LDN specification, the consumer is required to go through each of the steps in order because for instance the Inbox URL may change, and the only way for the consumer to be aware of this is to start the discovery process from the target. We can phrase this more clearly. Naturally, applications can still do what they prefer, however such behaviour is outside LDN’s scope.
In the revision of your review, could you please point out more specifically in what way Section 4.2 is appearing less detailed and less rigorous than 4.1? We believe that both sections have equal specificity since they describe the required steps.
We are going to clarify the fact that the ones that are tested only reflect the implementations which came forward to the W3C standardisation process, and as documented in the W3C GitHub repository. In the article, we had already linked to the source.
One conclusion that we are going to emphasise more explicitly is what’s stated in Section 6 “Analysis and Evaluation”, i.e. that the fast adoption of the LDN specification proves its feasibility. For future work, we would need inspect how related specifications e.g., paging, authentication/authorization, are used alongside LDN.
Anonymous Reviewer replied on
The paper is well written and mostly understandable, though it might be a good idea to rephrase some of the explanation in the section on Requirements and Design Considerations, specifically R4-B, which is confusing and not easy to understand.
I would also like more clarity on the following:
- Performance metrics to measure how well the protocol performs in practice.
- The most interesting part of the protocol is the (re)use of the received notification by the consumers. The paper should include explicit justification with concrete examples on why an application (consumer) would want to use an outdated notification exposed by some receiver. Most obvious examples are blog posts etc, but that seems to be the only obvious use case. It is also worth thinking about how a service like stack overflow can be re-purposed using LDN and what would be the benefits.
It is also easy to see why a formal semantics for the protocol would make sense. Apart from getting implementations to conform to a test suite, it is worth getting them to conform to a formal semantics specification. This is something that the authors should make a part of their future work.
I also see the evaluation as being quite limited, as there is no user-driven evaluation result that have been reported. While it is still early days for the protocol, without a clear idea of what it means for the consumers and how much it contributes to improving the overall data integration for a specific use-case or domain, it is hard to see the utility of implementing this as part of a larger system.
1 interaction
Sarven Capadisli replied on
Given that each application requires to follow the steps listed in Sections 4.1 “Sender to receiver interaction” and Section 4.2 “Consumer to receiver interactions” the metrics are dependent on the performance of client and server to do HTTP requests/responses, and their respective payloads. We will point this out more clearly.
How applications should advertise or consume notifications is use-case dependent. Therefore, it is difficult to justify if/how for example an “outdated notification” should or not, and how much of it be exposed. It would be premature to make generalisations from this.
Philipp Mayr replied on
signing in via orcid was possible.
Tobias Käfer replied on
Re: our ESWC discussion
Just out of curiosity, how do you know that an inbox is empty under the Open World Assumption?