Linked Specifications, Test Suites, and Implementation Reports
- Identifier
- https://csarven.ca/linked-specifications-reports
- In Reply To
- Call for Linked Research
- CFP for Developers’ track, The Web Conf 2018
- Notifications Inbox
- https://linkedresearch.org/inbox/csarven.ca/linked-specifications-reports/
- Annotation Service
- https://linkedresearch.org/annotation/csarven.ca/linked-specifications-reports/
- Published
- Modified
- License
- CC BY 4.0
Abstract
This article describes the semantic structure and linking of the W3C Recommendation Linked Data Notifications (LDN), its test suite, and implementation reports.
Semantically interlinking and detailed machine-readability of components related to Web standards and their implementations is novel, and can be useful for coherently documenting software projects and their conformance with specifications. Everything presented here is open source and reusable by other specifications (W3C standards or not), test suites, and implementations.
As a concrete example of the benefits of this approach, the LDN test suite is itself an LDN implementation for the purpose of automating the collection and aggregation of implementation reports which were used directly towards the formal standardisation process.
Introduction
A technical specification describes a set of requirements for a technology, for example data models, protocols, and application behaviour. The W3C publishes Technical Reports
— also known as specifications
and sometimes called standards
once they are widely adopted. These documents are intended to help different (current or future) implementations to have common core functionality and quality, comply with accessibility and internationalisation guidelines, and take security and privacy considerations into account. When an application, for instance, implements a specification, it can be checked against that specification’s conformance criteria for normative requirements. Specifications are typically accompanied with test suites to assist implementations to identify their conformance level as well as areas for improvement. Similarly, reports and feedback help specifications to improve and advance towards publication. Thus, a specification and conforming implementations are integral to ensuring valid and interoperable applications. In the context of the Web, specifications enable discoverability of data and services, data exchange, and predictability of side effects of certain requests.
In the wild, specifications and implementation reports are human-readable documents, and commonly the information within them is not machine-readable, at least from the perspective of exposing Linked Data on the Web. That is, there is a lack of globally identifiable and discoverable structured data in these documents, and they are not well linked to one another or to other resources on the Web; a machine consumer cannot reliably conduct a follow your nose
type of exploration, or provide search mechanisms without considerable customisation per resource. There are HTML templates for specifications which facilitate embedding of some structured data, but they tend to describe items like document level sectioning, references, contributors, or metadata. On the other hand, information on each specification requirement and conformance classifications remain as unstructured prose, or at least geared towards human consumption.
As for implementation reports, there is even less consistency across the board on how these documents are represented and accessed, let alone any definitive methods for data exchange or information retrieval.
Having the specifications and implementation reports appropriately interlinked and retrievable can facilitate their automated discovery and reuse. One attainable use case is to be able to find applications that match a certain conformance criteria, eg. in order to have fine-grained bundling of software packages. While this would typically include normative requirements, tests can potentially capture and reveal optional features of specifications. Prospective consumers of the compliance reports can be application developers finding appropriate software for use, as well as automatic software package managers.
This article describes the development of an interlinked, machine-readable W3C Recommendation, its test suite, and implementation reports as a whole. The W3C specification in question is Linked Data Notifications (LDN). The associated automated test suite covers each requirement of the specification with individual tests, and the test suite documentation is semantically linked with the specification itself accordingly. Once the tests have been run, the test suite generates a similarly linked implementation report. This report is submitted using LDN itself as the notification mechanism (more on this later). The listing of implementation reports (software conforming to the specification) is thus automatically updated. Figure 1 depicts an overview of linking the LDN specification, its test suite, the generated implementation report for the dokieli project, reports summary, and an article citing the specification.
The information patterns discussed in the specification and the implementation reports sections should be reusable across other specifications and related components. Sources are available from:
- The specification: https://www.w3.org/TR/ldn/
- The test suite: https://linkedresearch.org/ldn/tests/
- Implementation reports summary and individual reports: https://linkedresearch.org/ldn/tests/summary
The test suite uses mayktso (https://github.com/csarven/mayktso) as the LDN receiver, but any conformant receiver implementation will work here.
The prefixes and namespaces that are used in this article are listed under the document convention section.
Specification
Linked Data Notifications (LDN) is a W3C Recommendation, published in May 2017, which defines a protocol for discovery, creation and reuse of machine-readable notifications over HTTP.
The W3C process requires the creation of a test suite, and the submission of reports about implementations which pass any or all of the tests. The LDN editors took the liberty to both use this process to exemplify the LDN protocol itself, as well as to generate discoverable Linked Data about the specification and its implementations.
The LDN technical report has an HTML+RDFa representation. It used existing vocabularies (as of 2017-05). The document is a type of a doap:Specification and it has provenance information such as:
prov:wasRevisionOffor the earlier version of the specification.schema:datePublishedfor the publication date.schema:authorandschema:contributorof the document and their partial descriptions.doap:repositorypointing at the specification’s repository, anddoap:bug-databasefor issues.rdfs:seeAlsofor related stuff and the test suite’s location.as:inReplyToprovides some context for the specification.xhv:licensefor license (W3C default).
This metadata covers what is required by W3C publishing standards.
It also has some discourse components like schema:abstract, schema:description for each section with schema:name for short labels, and schema:hasPart to relate nested sections. Some sections have specific types, eg. deo:Introduction, deo:Acknowledgements, and skos:Concept.
In order to specify how the specification’s requirements are linked to from the implementation reports, we need to look at the specification as something that provides the definitions of the concepts which the implementation reports can refer to in their assertions.
One way to define the shape of the data structure is done with the RDF Data Cube vocabulary (QB), and the definitions for its components with the Simple Knowledge Organization System (SKOS) vocabulary. The Evaluation and Report Language (EARL) vocabulary is used to describe the test results and facilitate their exchange between applications.
The qb:DataStructureDefinition (DSD) describes the shape of the multi-dimensional data which will be used in the reports, and is embedded in the LDN specification. In a hypercube, the dimensions serve to identify an observation, and the measure is for the observed value. The DSD is provided in the specification so that systems familiar with the QB vocabulary can have a sense of the structure independently of the actual use of EARL in the reports. Furthermore, alternative test suites can be built reusing the same DSD.
ldn:data-structure-definitiona qb:DataStructureDefinition ;qb:component[ qb:dimension earl:subject ] ,[ qb:dimension earl:test ] ,[ qb:dimension earl:mode ] ,[ qb:measure earl:result ] .
The 3 dimension properties of type qb:DimensionProperty (ie. earl:subject, earl:test, earl:mode), and 1 measure property is of type qb:MeasureProperty (ie. earl:result):
earl:subjectfor the application that’s being tested.earl:testfor the test criterion.earl:modefor how the test was conducted.earl:resultfor the test result.
LDN has conformance classes for each implementation role: sender, receiver, and consumer. A skos:ConceptScheme is defined per role, and each concept scheme skos:hasTopConcept referring to an individual requirement as a skos:Concept. They all have their skos:prefLabel and skos:definition, and encapsulate the human-visible text of the requirements, for example: senders are required to send the payload in JSON-LD.
<>schema:hasPart ldn:ldn-tests-sender .ldn:ldn-tests-sendera skos:ConceptScheme ;skos:prefLabel "LDN Tests Sender"@en ;skos:hasTopConcept ldn:test-sender-header-post-content-type-json-ld .ldn:test-sender-header-post-content-type-json-lda skos:Concept ;skos:topConceptOf ldn:tests-sender ;skos:definition "the body of the POST request MUST contain the notification payload in JSON-LD with header Content-Type: application/ld+json"@en .
Each requirement represented as a concept has an HTML id attribute and a URI. These URIs correspond with observations’ dimensions values in the test reports.
Implementation Reports
The motivation for the test suite and the generated reports is to have their information equally consumable by human and machines. The human-friendly parts typically have an HTML user interface, and so making them also machine-processable extends their reuse. We do this by incorporating the structured data for the report in the test suite itself so that a report URL can accommodate both cases. This means that the test suite frames its expressions using the EARL and QB vocabularies, resulting in reuse of globally identifiable language — this is in contrast to creating an application-centric language that is virtually disconnected from everything else.
A test report gets generated when a tester submits the results of running the LDN Test Suite. The report contains the outcome of all test criterion as multi-dimensional data for a given type of implementation (sender, receiver, consumer).
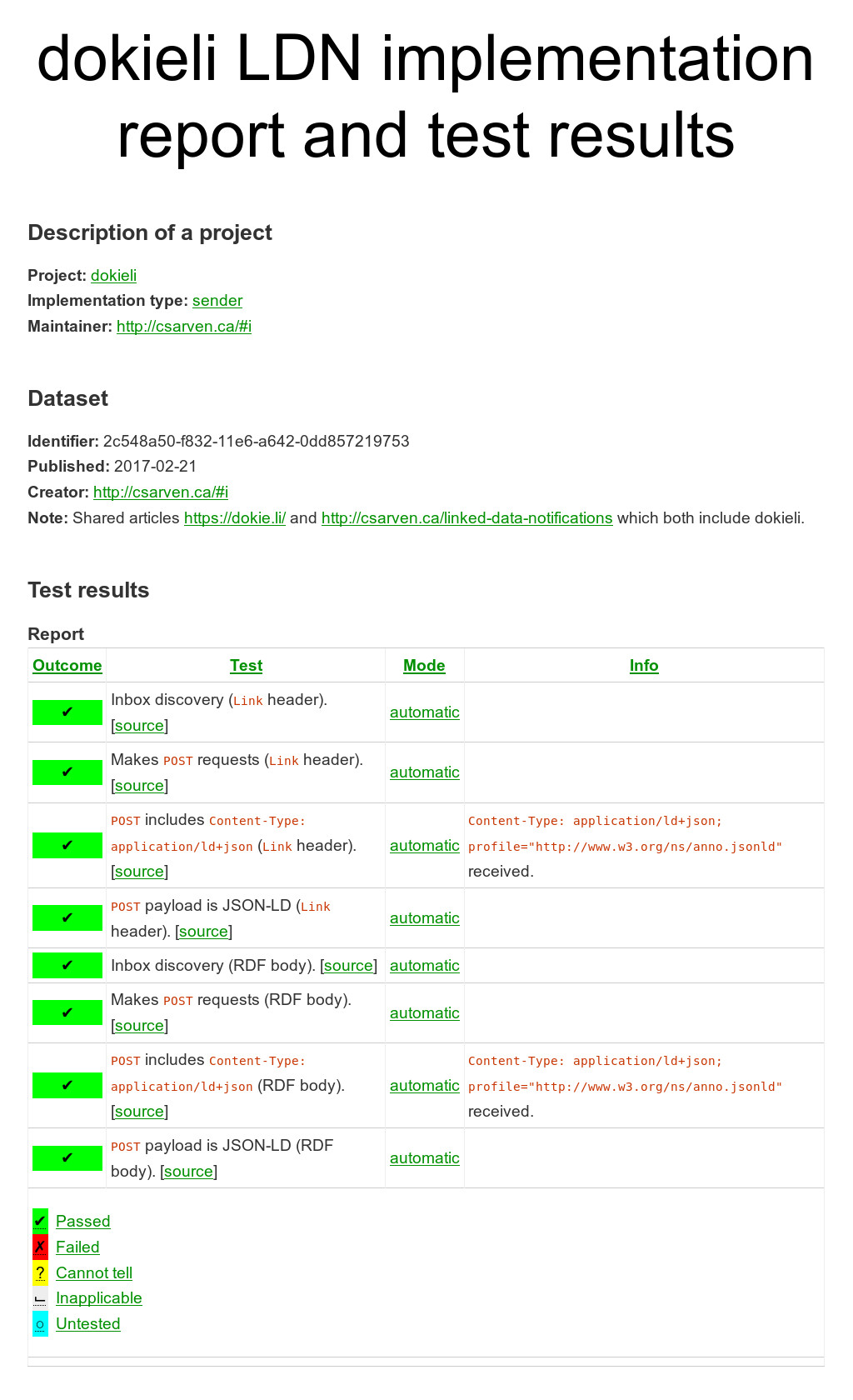
All reports have their own URLs, and a representation in HTML+RDFa (optionally in other RDF serialisations via content negotiation at this particular test server). See for example dokieli’s implementation report and test results as a sender (figure 2). This provides the human-visible information, eg. what was tested and the results also in machine-readable form. The report can be seen as a dataset composed of observations based on the structure that was specified in the specification. Hence, each test report is a qb:DataSet (and generally equivalent in as:Object) where its qb:structure refers to https://www.w3.org/TR/ldn/#data-structure-definition. The dataset has as:published and as:actor for the agent that initiated the test and generated the report. The report may be accompanied with an additional as:summary. An example report at https://linkedresearch.org/ldn/tests/reports/2c5af2f0-f832-11e6-a642-0dd857219753 has the following core information:
<>a qb:DataSet ;qb:structure ldn:data-structure-definition .<https://linkedresearch.org/ldn/tests/reports/2c5af2f0-f832-11e6-a642-0dd857219753#test-sender-header-post-content-type-json-ld>a qb:Observation, earl:Assertion ;qb:dataSet <> ;earl:subject <https://dokie.li/> ;earl:test ldn:test-sender-header-post-content-type-json-ld ;earl:mode earl:automatic ;earl:result [a earl:TestResult ;earl:outcome earl:passed ;earl:info "<code>Content-Type: application/ld+json; profile="http://www.w3.org/ns/anno.jsonld"</code> received."^^rdf:HTML ] .
The test results are provided in an HTML table, where each test is expressed as an qb:Observation (and equivalent earl:Assertion) in RDFa containing:
- a
earl:subjectthat refers to the URI of the application, eg. dokieli, adoap:Projectas an LDN Sender. - a
earl:testwith the range being one the requirements (concepts) from the specification. - a
earl:modereferring to one of the EARL test modes that were carried out: automatic, manual, semi-automatic, undisclosed, unknown. - and a
earl:resultthat gives information on the testearl:outcome: passed, failed, inapplicable, cannot tell, untested, as well as detailedearl:infoabout the particular experiment.
The implementation test report has some basic information linking to the doap:Project with a doap:name, and its doap:maintainer.
All of the sender, receiver, and consumer reports are available in separate aggregate tables in LDN Tests Summary. The summary is a void:Dataset where each report is linked as a void:subset. This makes individual reports alternatively findable if the exploration starts from the summary of all test results.
Usage
At this point we have the test reports referring to specific parts of the specification. We can continue to further extend this linked data graph with other things. One extension possibility is to describe individual implementations further by stating that they implement the specification, or parts of it. This is a relatively simple exercise of making statements about the project such that it doap:implements the specification: https://www.w3.org/TR/ldn/, which doap:programming-languages it uses, the project’s doap:repository and so on. For more details, see https://dokie.li/ on how the DOAP vocabulary is used as well as a reference to LDN.
Coming from the direction of the reports, we can also precisely know the conformance level of each implementation. This is useful to deterministically know that an implementation conforms to specification’s core requirements, which is necessary for interoperability, as well as their coverage of the optional features.
The LDN Tests Suite puts the LDN protocol into practice by acting as an LDN receiver implementation (based on mayktso). It also acts as a sender and consumer LDN implementation. Each part of the test suite (for Senders, Receivers, and Consumers) advertise an ldp:inbox. Upon completion of a run of the tests, the system generates the report data and sends an LDN notification to the Inbox. The payload of the notification is the full report as RDF.
As an LDN Consumer, the test suite generates the summary of the reports by fetching and processing Inbox contents. The notifications are aggregated automatically, and the semantics of the submitted reports are retained.
Once the notifications are fetched from the reports Inbox, an HTML+RDFa representation (alternatively in other RDF serialisations upon content negotiation) of the response is returned for a human- and machine-readable summary. The services are decoupled; that is, an implementer may generate their report independently of the test suite, and submit it vial the standard LDN protocol. Furthermore, projects can implement their own consumers and reuse the report data generated by the test suite directly, for example to demonstrate to potential users their conformance to the LDN specification.
An opportunity arises when the specification is available with structured data by way of having ordinary Web articles simply refer to different sections and concepts. For example, the scholarly article on Linked Data Notifications uses the CiTO vocabulary to cite the specification with cito:citesAsAuthority. Another peer reviewed article, Decentralised Authoring, Annotations and Notifications for a Read-Write Web with dokieli, contextually cites the specification with cito:citesAsPotentialSolution from its architectural overview section, as well as the LDN Test Suite with cito:citesAsAuthority from its adoption section. This is useful in that we can have articles linked to what is already available with minimal effort. Including this article that you are currently reading and interacting with.
The realisation here is that we have everything operating in a way that is interoperable: the specification, test suite, discovery of the reports, and academic articles, all reusing existing vocabularies.
Discussion
The work here can serve as a demonstration or a guideline on what can be achieved by similar types of specifications and test suites. EARL and QB provide the foundations to connect the dots
in these documents for the purpose of improving quality assurance, validation, and sharing the output of a working group as structured data on the Web.
The key takeaways are:
- Human and machine-readable documents via HTML+RDFa are feasible for specifications and implementation reports.
- The connection between EARL and the QB vocabulary is suitable for multi-dimensional data without having to define new component specifications for the data cube.
- Individual observations (test results) can be identified and discovered through contextual links in the specification, with the use of EARL and QB vocabularies.
- The LDN protocol can support the possibility to send, receive and consume notifications about the implementation reports, as well as help with their discovery and reuse.
- It is possible for other documents to refer to specific parts of the specification, test suite and reports.
We conclude by offering some suggestions to specification editors, test suite builders, and implementers:
Specification editors should consider taking advantage of the level of expressivity that is possible and reuse the existing human-visible content towards machine-readability.
It requires a considerable amount of work to devise the shape of test reports, so basing the test suite on EARL and QB can simplify and streamline this process. The approach also benefits from making the reports identifiable, discoverable, exchangeable, and reusable on the Web.
Lastly, implementations should have machine-readable descriptions, eg. at their homepages, so that the test reports can refer to them and provide the possibility to collect more detailed information about their features.
Acknowledgements
The work on the LDN specification and its test suite was done in collaboration with Amy Guy. Thanks to Jindřich Mynarz, Stian Soiland-Reyes, and Raphaël Troncy for giving early feedback on this article.
Document Convention
as- https://www.w3.org/ns/activitystreams#
cito- http://purl.org/spar/cito/
doap- http://usefulinc.com/ns/doap#
earl- http://www.w3.org/ns/earl#
ldn- https://www.w3.org/TR/ldn/#
prov- http://www.w3.org/ns/prov#
qb- http://purl.org/linked-data/cube#
rdf- http://www.w3.org/1999/02/22-rdf-syntax-ns#
schema- http://schema.org/
skos- http://www.w3.org/2004/02/skos/core#
void- http://rdfs.org/ns/void#
xhv- http://www.w3.org/1999/xhtml/vocab#
Interactions
2 interactions
Anonymous Reviewer replied on
This article describes the semantic linking of an existing W3C Recommendation named Linked Data Notifications and accessible at https://www.w3.org/TR/ldn/. The paper reports also a test suite and implementation reports. In principle, the interlinking of a specification and turning it into a machine-readable content is very valuable since this can foster the usage of autonomous systems to verify and assess automatically the adoption of a standard from a software component that follows a given (machine-readable) specification.
The paper is well written: clear problem formulation, and clear description of development and implementation. The reported demonstration scenario, however, only provides pointers and does not report discussions about the benefits. The intuition is that this is useful, but reading this paper I'm not convinced that I would replicate this in other scenarios. This is a shortcoming. What proposed well fits the developers' track.
Anonymous Reviewer replied on
The author provides a report along with code that improves the way W3C recommendations publish their implementation reports as well as enrich them with semantic metadata and interlink them. I find this topic as a very good match to focus of this track and suggest it's acceptance.